


Feed Forward in Neural Networks
- Flow of Information in Neural Networks
- Dimensions in a Neural Network
- Output
- Batch Processing
- Takeaways
- Questions
- References
Flow of Information in Neural Networks
In artificial neural networks, the output from one layer is used as input to the next layer. Such networks are called feedforward neural networks. This means there are no loops in the network - information is always fed forward, never fed back.
Comprehension - Count of Pixels
The figure below shows an artificial neural network which calculates the count of the number of pixels which are ‘on’, i.e. have a value of 1. It further amplifies the output by a factor of 2; so if 2 pixels are on, the output is 4, if 3 pixels are on the output is 6 and so on.
We’ll call the input layer as layer 0 or simply the input layer. The other three layers are numbered 1, 2 and 3 (3 is the output layer).
![]()
The weight matrices of the 2 hidden layers and the third output layer are shown above. The first and the second neurons of the (hidden) layer 1 represent the number of ‘on’ pixels in row 1 and 2 respectively. The second (hidden) layer amplifies the output of layer 1 by a factor of 2 and the third (output) layer sums up the amplified counts.
The biases are all 0 and the activation function is $\sigma(x) = x$
Let's make one minor modification in our network - let’s represent the input with 4 pixels as a vector with pixels counted clockwise. Thus the input shown in the figure is $\begin{bmatrix}1\0\1\0\end{bmatrix} (and not $\begin{bmatrix}1\0\0\1\end{bmatrix}$) which is called the row-major order)$
If the output of the network is 6, then the possible inputs are
| Input Matrix | Valid |
|---|---|
| \begin{bmatrix}0\1\1\1\end{bmatrix} | Yes |
| \begin{bmatrix}1\0\1\1\end{bmatrix} | Yes |
| \begin{bmatrix}0\0\1\1\end{bmatrix} | No |
| \begin{bmatrix}1\1\0\1\end{bmatrix} | Yes |
- The on pixels are represented by number 1. It amplifies the output by a factor of 2. So if 3 pixels are on, then output is 6.
For the input $\begin{bmatrix}1\1\0\0\end{bmatrix}$, the output of the first neuron of hidden layer 1 is
- 2
- This neuron represents the number of pixels that are on row 1, which is 2
Now, you want to modify the weights of layer-1 so that the first and the second neurons in the hidden layer 1 represent the number of ‘on’ pixels in the first and second column of the input image respectively. This should be true for all possible inputs into the network. What should be $W^1$? (note that the input vector is created by counting the pixels clockwise)
- $\begin{bmatrix}1&0&0&1\0&1&1&0\end{bmatrix}$
- The first neuron’s output will be the first row of w1 multiplied by the input vector.
- If the input vector is [1 0 0 1], i.e both pixels in the first column are on, then the output of neuron 1 should be 2.
- For [1 0 0 0], the output should be 1.
- In general, for the first neuron, the output should sum up the first and the fourth element of the input.
- Thus row 1 should be [1 0 0 1].
- Similarly, for the second neuron, the output should sum up the second and the third element of the input. So the second row should be [ 0 1 1 0].
Let's assume that each elementary algebraic operation, such as multiplication of two numbers, applying the activation function on a scalar f(x), etc. takes 0.10 microseconds (on a certain OS in python). Note that addition is NOT included as an operation. For the network discussed above, how much time would it take to compute the output from the input given all the parameters?
Hint: There are 3 weight matrices $W^1, W^2, W^3$ of sizes $2\times 4, 2\times 2, 1\times 2$. The activation function is applied to each of the three layers' input to compute $h^1, h^2, h^3$.
- 1.9 microseconds
- Layer 1
- For the weight matrix $W^1$: It is a (2\times 4)(4\times 1) product, thus has 8 multiplications (one for each row).
- The activation function is then applied to the 2 neurons.
- Thus 10 x 0.1 ms is the time taken till layer 1's output
- Layer 2
- For layer 2, $W^2$, it is a 2 x 2 product + activation function applied on 2 scalars.
- So far, we have 8 + 2 + 4 + 2 = 16 operations
- Layer 3
- For layer 3, its a (2x1)(1x2) matrix product + 1 activation operation
- Thus, we have 16 + 3 = 19 operations which will take 1.9 microseconds
Dimensions in a Neural Network
Input Vector
- The input vector dimensions are just the number of features times 1 making it a column vector.
- Ex: (5, 1) or (5, ) is an input vector, while (5, 5) or (1, 5) is not.
- Note that by default vectors are assumed to be column vectors unless state otherwise.
Weight Matrix
- The weights are always in a matrix form.
- Ex: (5, 5) or (3, 5) or (7, 2) are valid dimensions for weight matrices
- Note that the weight matrix should have column dimension same as the input vector it is going to receive since we take the dot product of the weight matrix ($\mathbf M$) with input vector ($\vec v$) as follows:
M.v. - As per the rules of matrix multiplication, if Matrix $\mathbf A$ has dimension $(a, b)$ while B has dimensions $(c, d)$ then their dot product $(\mathbf A . \mathbf B)$ can only be taken if $b = c$
Example
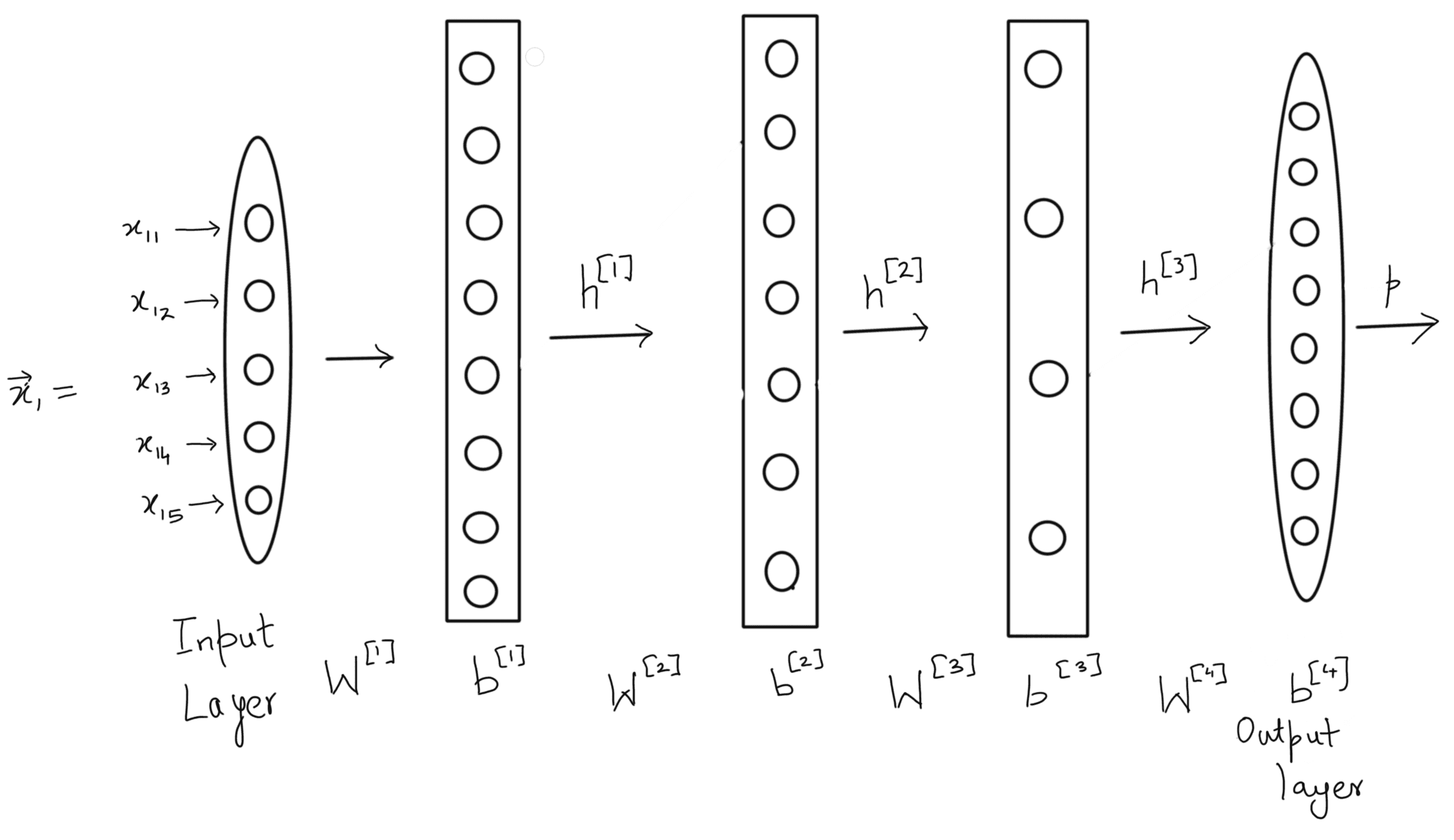
Dimension of input vector $\vec x_1$
- (5, 1)
- There are 5 neurons in the input layer. Hence (5,1). By default, a vector is assumed to be a column vector.
Dimensions of $\mathbf W^1; \text{to}; \mathbf W^4$
- $(8, 5), (7, 8), (4,7); \text{and}; (4,8)$
- The dimensions of $\mathbf W^l$ are defined as (number of neurons in layer l, number of neurons in layer l-1)
Dimensions of the output vectors of the hidden layers $\vec h^1$ and $\vec h^2$
- $(8,1);\text{and};(7,1)$
- The dimension of the output vector for a layer l is (number of neurons in the layer, 1)
The dimension of the bias vector is the same as the output vector for a layer l for a single input vector. True or False.
- True
What is the number of learnable parameters in this network? Note that the learnable parameters are weights and biases.
- 183
- The weights have 40, 56, 28, 32 individual parameters(the weight elements). The layers have 8, 7, 4, 8 biases respectively.
Output
Output of a layer
- Weight matrix of layer l is multiplied by hidden layer l-1's output (input vector if it's first output we are considering)
- $\mathbf W^{[l]}.\vec h^{[l-1]}$
- Add bias
- $\mathbf W^{[l]}.\vec h^{[l-1]} + \vec b$
- Apply activation function
- $\vec h^{[l]} = \sigma(\mathbf W^{[l]}.\vec h^{[l-1]} + \vec b)$
Elaborating on Dimensions
Say, dimension of $\vec h^1 = 5$ and dimension of $\vec h^2 = 6$,
then weight matrix $\mathbf W^2$ will be of the dimension $6 \times 5$
You can try with multiplying two matrices and checking their dimensions to understand why that must be true.
import numpy as np
A = np.array([[2, 7, 1], [-2, 1, 8], [3, 4, -2]])
B = np.array([[8, 1, 3], [3, 5, 8], [7, -2, -4]])
C = A @ B
print(C)
print(A.shape, B.shape, C.shape)
print('---')
A = np.array([[2, 7, 1], [-2, 1, 8], [3, 4, -2], [1, 2, 3]])
B = np.array([[8], [3], [7]])
C = A @ B
print(C)
print(A.shape, B.shape, C.shape)
print('---')
D = np.dot(A, B)
print(D)
print(D.shape)Procedure
The procedure to compute the output of the $i^{th}$ neuron in the layer l is:
- Multiply the $i^{th}$ row of the weight matrix with the output of layer l-1 to get the weighted sum of inputs
- Convert the weighted sum to cumulative sum by adding the $i^{th}$
bias term of the bias vector
- Apply the activation function, $\sigma(x)$ to the cumulative input to get the output of the $i^{th}$ neuron in the layer l
$h^1 = \begin{bmatrix} h_1^1\h^1_2\h^1_3\h^1_4 \end{bmatrix} = \sigma(W^1.x_{i}+b^1) = \begin{bmatrix} \sigma(w^1_{11}x_1 + w^1_{12}x_2 + w_{13}^1x_3 + b_1^1)\ \sigma(w^1_{21}x_1 + w^1_{22}x_2 + w_{23}^1x_3 + b_2^1)\ \sigma(w^1_{31}x_1 + w^1_{32}x_2 + w_{33}^1x_3 + b_3^1)\ \sigma(w^1_{41}x_1 + w^1_{42}x_2 + w_{43}^1x_3 + b_4^1) \end{bmatrix}$
Final Output
- Depending on the type of the problem, the output layer can have different number of neurons
- For regression, there will be a single output neuron
- For binary classification, there will be two output neurons
- For multiclass classification, there will be as many output neurons as there are classes.
- The first neuron outputs the probability for label 1, the second neuron outputs the probability for label 2 and so on.
- The output of a feedforward network is obtained by applying the activation function on the output layer
Algorithm
- $h^0 = x_{i}$
- for $\vec l$ in $[1, 2, \ldots, L]:$
- $h^l = \sigma(W^l.h^{l-1} + b^l)$
- $p = f(h^l)$
- The last layer (the output layer) is different from the rest, and it is important how we define the output layer.
- Here, since we have a multiclass classification problem (the MNIST digits between 0-9), we have used the softmax output which we had defined in the previous session:
$p_{i} = \begin{bmatrix}p_{i_1}\p_{i_2}\p_{i_3}\\ldots\p_{i_c}\\end{bmatrix}$ where $\displaystyle p_{ij} = \frac{e^{w_j.h^L}}{\sum_{t=1}^c e^{w_t.h^L}}$ for $j = [1,2,...,c]$ and c = number of classes
This operation is often called as normalizing the vector $p_i$
Complete Algorithm Steps
- $h^0 = x_{i}$
- for $\vec l$ in $[1, 2, \ldots, L]:$
- $h^l = \sigma(W^l.h^{l-1} + b^l)$
- $p_i = e^{W^o.h^L}$
- $p_i = \text{normalize}(p_{i})$
Note that $W^o$ (the weight of the output layer) can be written as $W^{L+1}$ as well.
Example
Consider $W^o = \begin{bmatrix}3&4\1&9\6&2\end{bmatrix}$ and $h^2 = \begin{bmatrix}1\2\end{bmatrix}$ and bias is 0. What will be $W^o.h^2$?
- $\begin{bmatrix}11\19\10\end{bmatrix}$
Softmax output vector $\vec p$ (output of 3rd layer).
- $\begin{bmatrix}0.00034\0.99954\0.00012\end{bmatrix}$
- The probability order would be $3<1<2$ for the class labels
What is the predicted label?
- 2
- As the highest probability is for the neuron representing label 2, it is the predicted label.
Batch Processing
- It would inefficient to do a for loop type computation for each input row of the whole data
- We use batch processing to vectorize the process
- Small batches of the input data are created
- Each batch is processed one by one
- The calculation for the whole batch is done in one, almost as if only one data point is being fed
- Calculation is parallelized due to blockwise property of matrix multiplication
- The algorithm is similar to the one for single data point
Algorithm
- $H^0 = B$
- for $l$ in $[1,2,...,L]$:
- $H^1=\sigma(\mathbf W^l.\mathbf H^{l-1} + \vec b^l)$
- $P = \text{normalize(exp}(\mathbf W^o.\mathbf H^L + \vec b^o))$
- Note that we have used upper case H & P to denote batch processing
- $H^l$ and $P$ are matrices whose $i^{th}$ column represents the $\vec h^l$ and $\vec p$ vectors respectively of the $i^{th}$ data point.
- The number of columns in these 'batch matrices' is equal to the number of data points in the batch $m$
Example
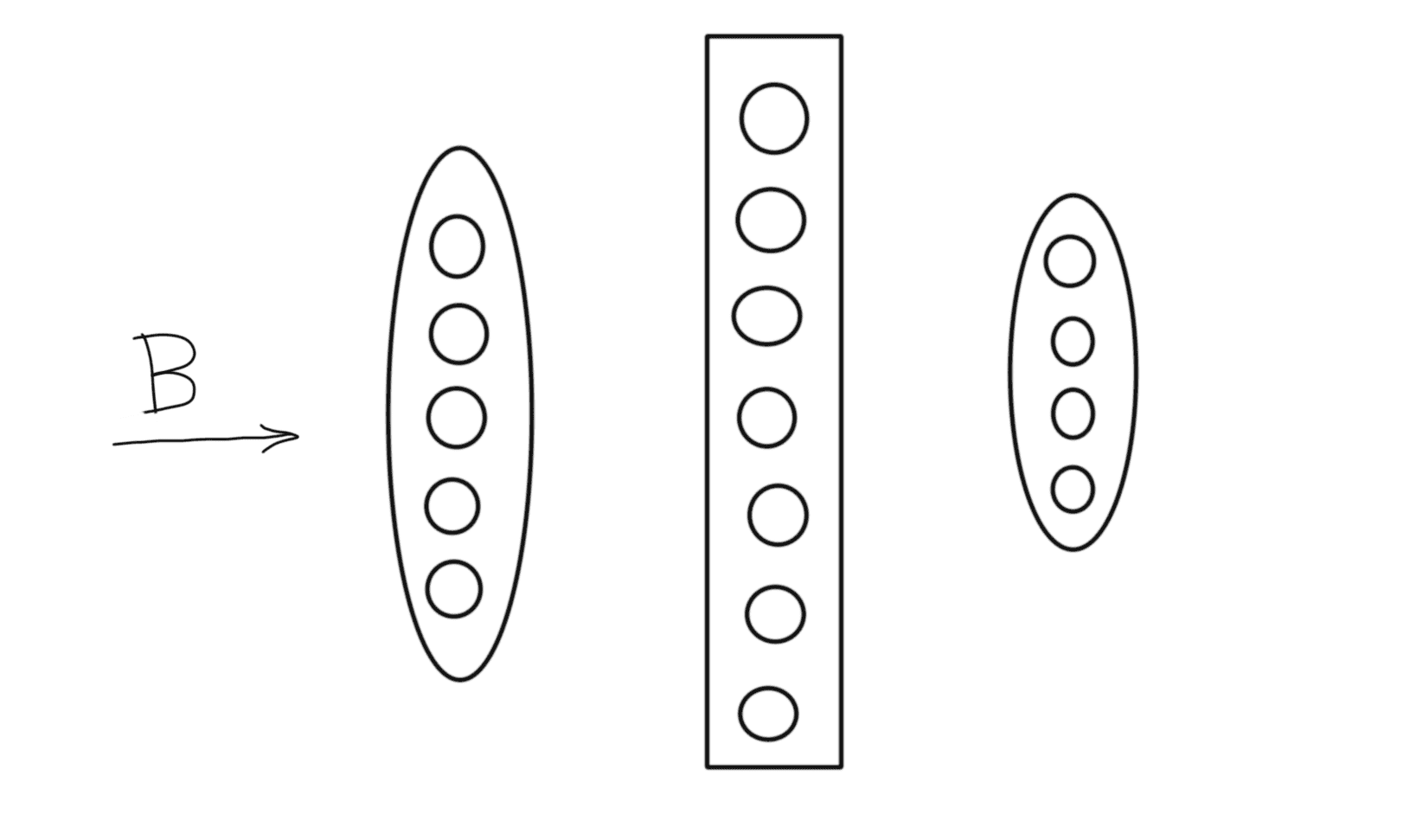
What is the dimension of the network output matrix $P$
- $(4, 50)$
- There are 4 neurons in the output layer. Hence, for every input data point, there will be an output vector of shape (4,1). Since there are 50 such data points, the shape of the matrix P is (4,50).
What is the dimension of the output matrix out of the first hidden layer, that is $H^1$
- There are 7 neurons in the hidden layer 1. Hence, for every input data point, there will be an output vector of shape (7,1). Since there are 50 such data points, the shape of the matrix $\mathbf H^1$ is (7,50).
What is the dimension of the input batch $\mathbf B$
- (5, 50)
- There are 50 input data points and there are 5 neurons for each input data point. Hence, dimension = (5,50)
Takeaways
- Information flows in one direction in feed forward networks (from layer l-1 to l)
- The computation for output mostly boils down to weights * inputs + bias after which an activation function is applied
- Block matrix multiplication makes this whole process fast and paralleziable by using fast GPUs.
Questions
Consider a neural network with 5 hidden layers. Choose the ones that are correct in the feedforward scheme of things.
| Statement | True / False |
|---|---|
| The output of the 2nd hidden layer can be calculated only after the output of the 3rd hidden layer in one feed forward pass. | F |
| The output of the 3rd hidden layer can be calculated only after the output of the 2nd hidden layer in one feed forward pass. | T |
| The output of the 3rd hidden layer can be calculated only after the output of the 4th hidden layer in one feed forward pass. | F |
| The output of the 5th hidden layer can be calculated only after the output of the 2nd hidden layer in one feed forward pass. | T |
- In feed forward, output of layer 'l' can be calculated only after the calculation of the output of all the 'l-1' layer.
Consider a neural network with 5 hidden layers. You send in an input batch of 20 data points. What will be the dimension of the output matrix of the 4th hidden layer if it has 12 neurons?
- (12, 20)
- Dimension = (number of neurons in the layer, size of the batch)
Consider a neural network with 5 hidden layers. You send in an input batch of 20 data points. How will you denote the weight matrix between hidden layers 4 and 5?
- $W^5$
- $W^l$ is the weight matrix between the layer l and l-1
Consider a neural network with 5 hidden layers. You send in an input batch of 20 data points. The weight matrix $W^3$ has the dimension (18,12). How many neurons are present in the hidden layer 2?
- 12
- Matrix dimension = (number of neurons in the layer in layer l, number of neurons in layer 'l-1')
Imagine you have a neural network in which a layer l has dimension (128, 64). How many neurons are present in layer l?
- 128
- Matrix dimension = (number of neurons in the layer in layer l, number of neurons in layer 'l-1')